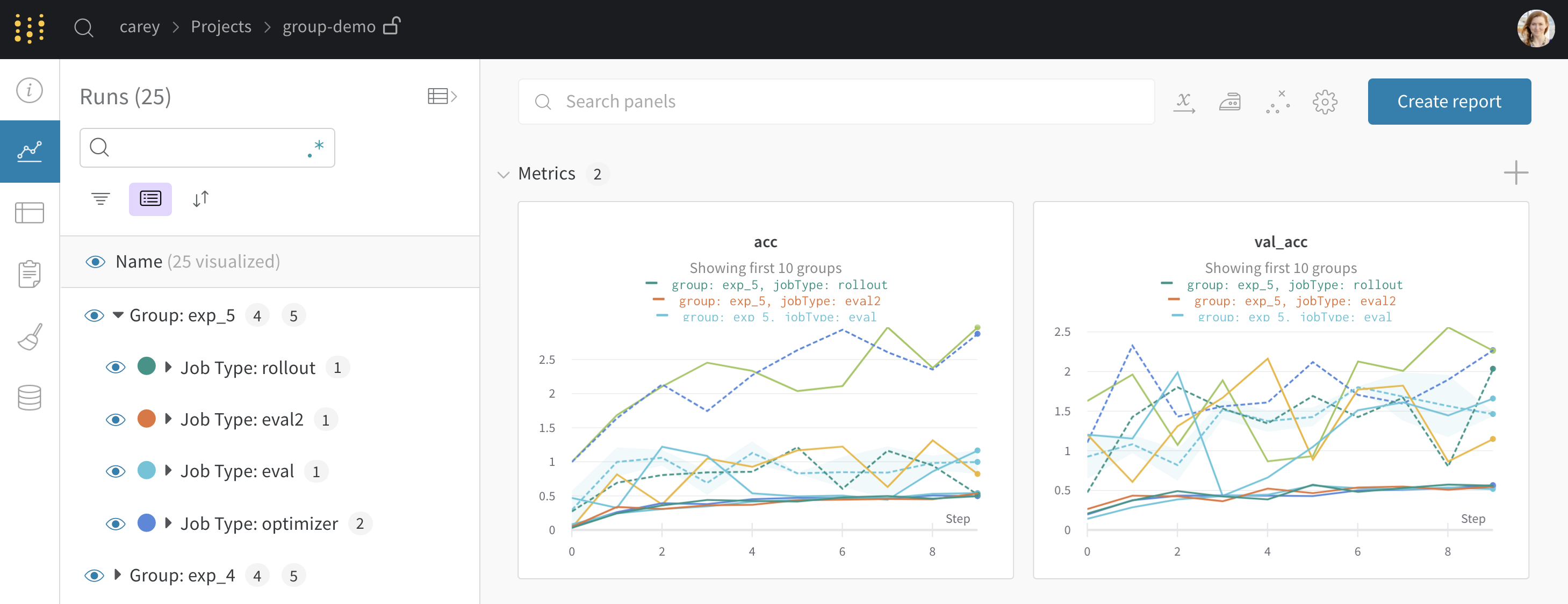
Group Runs
Group individual jobs into experiments by passing a unique group name to wandb.init().
Use Cases
- Distributed training: Use grouping if your experiments are split up into different pieces with separate training and evaluation scripts that should be viewed as parts of a larger whole.
- Multiple processes: Group multiple smaller processes together into an experiment.
- K-fold cross-validation: Group together runs with different random seeds to see a larger experiment. Here's an example of k-fold cross-validation with sweeps and grouping.
There are three ways to set grouping:
1. Set group in your script
Pass an optional group and job_type to wandb.init(). This gives you a dedicated group page for each experiment, which contains the individual runs. For example:wandb.init(group="experiment_1", job_type="eval")
2. Set a group environment variable
Use WANDB_RUN_GROUP to specify a group for your runs as an environment variable. For more on this, check our docs for Environment Variables. Group should be unique within your project and shared by all runs in the group. You can use wandb.util.generate_id() to generate a unique 8 character string to use in all your processes— for example, os.environ["WANDB_RUN_GROUP"] = "experiment-" + wandb.util.generate_id()
3. Toggle grouping in the UI
You can dynamically group by any config column. For example, if you use wandb.config to log batch size or learning rate, you can then group by those hyperparameters dynamically in the web app.
Distributed training with grouping
Suppose you set grouping in wandb.init(), we will group runs by default in the UI. You can toggle this on and off by clicking the Group button at the top of the table. Here's an example project generated from sample code where we set grouping. You can click on each "Group" row in the sidebar to get to a dedicated group page for that experiment.
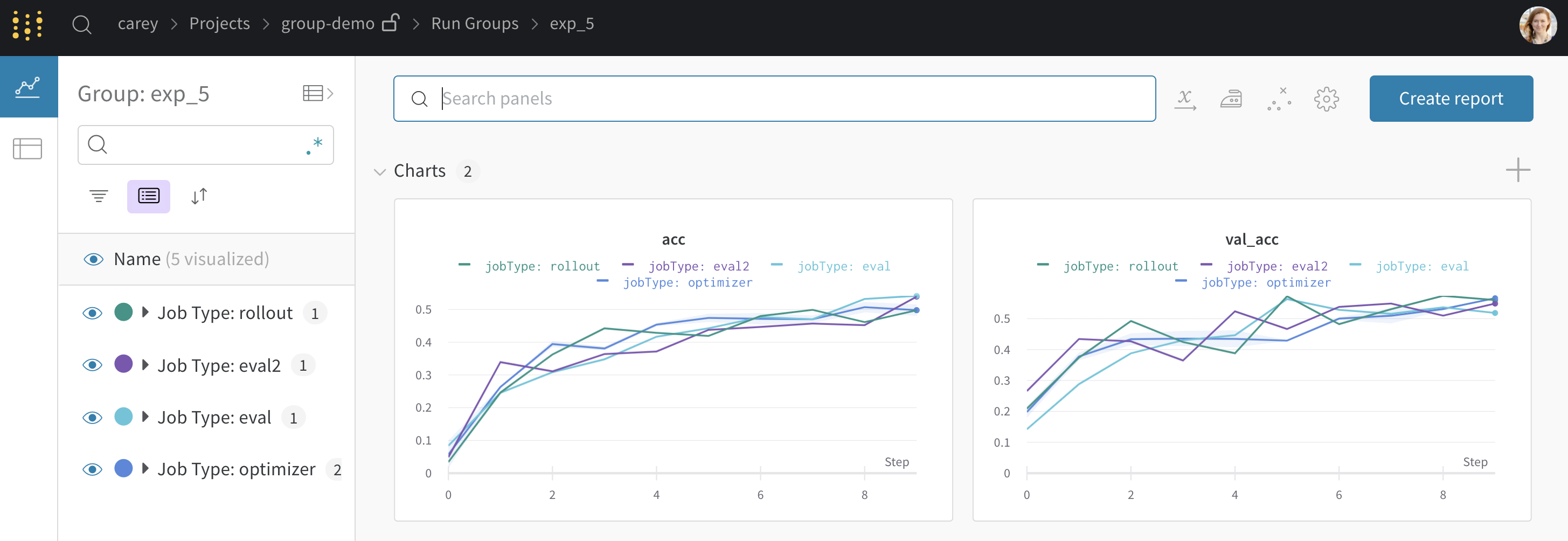
From the project page above, you can click a Group in the left sidebar to get to a dedicated page like this one:
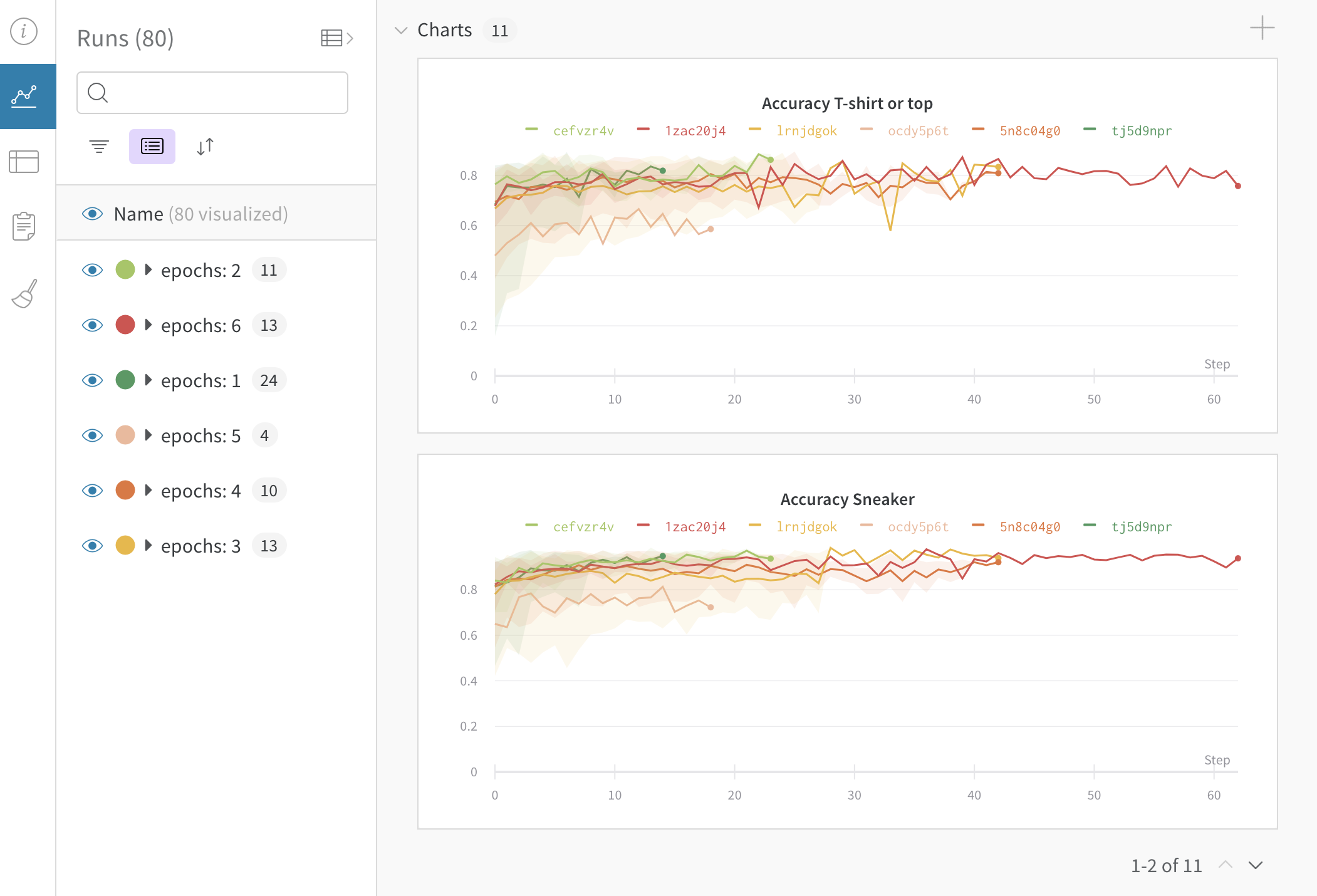
Grouping dynamically in the UI
You can group runs by any column, for example by hyperparameter. Here's an example of what that looks like:
- Sidebar: Runs are grouped by the number of epochs.
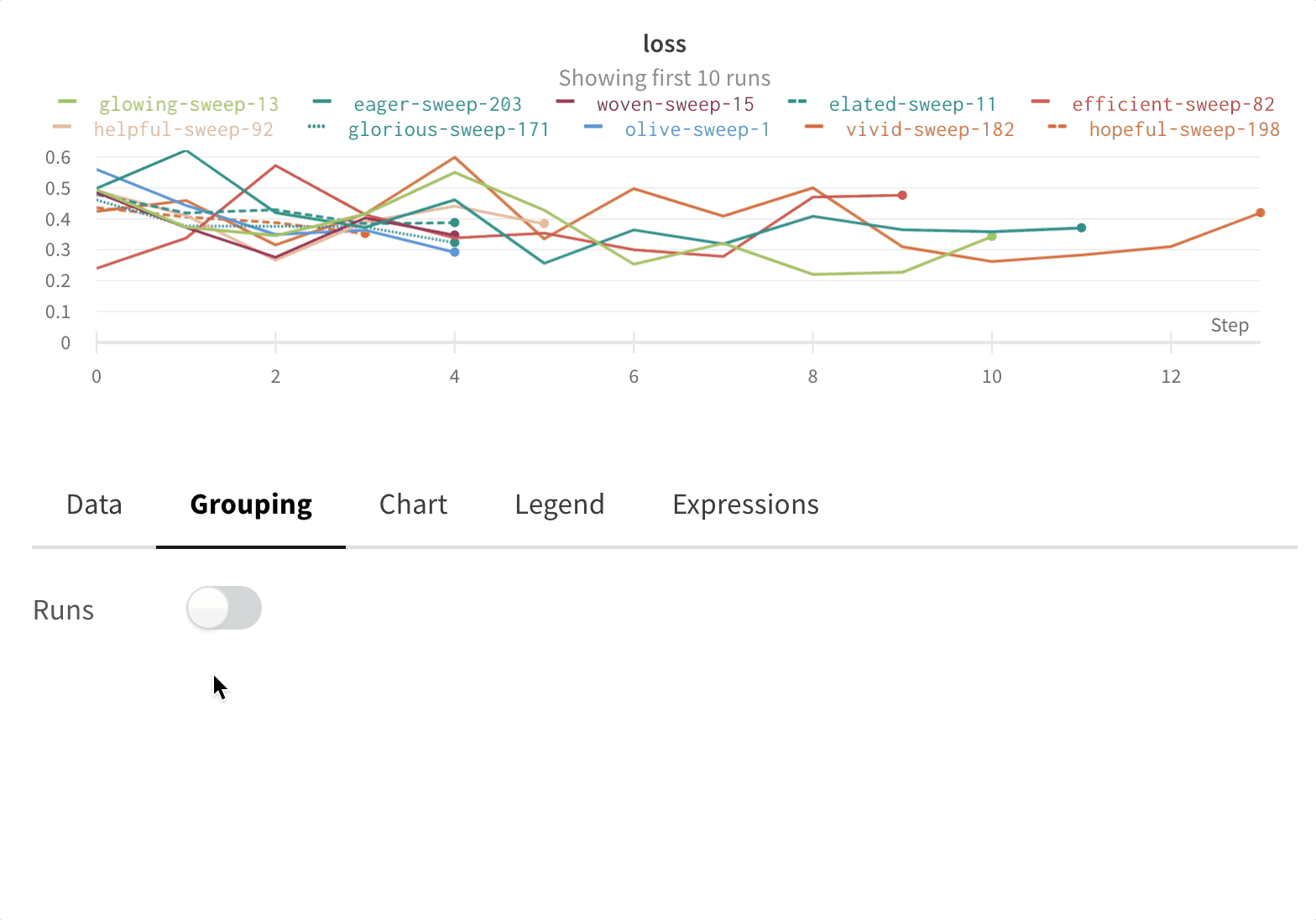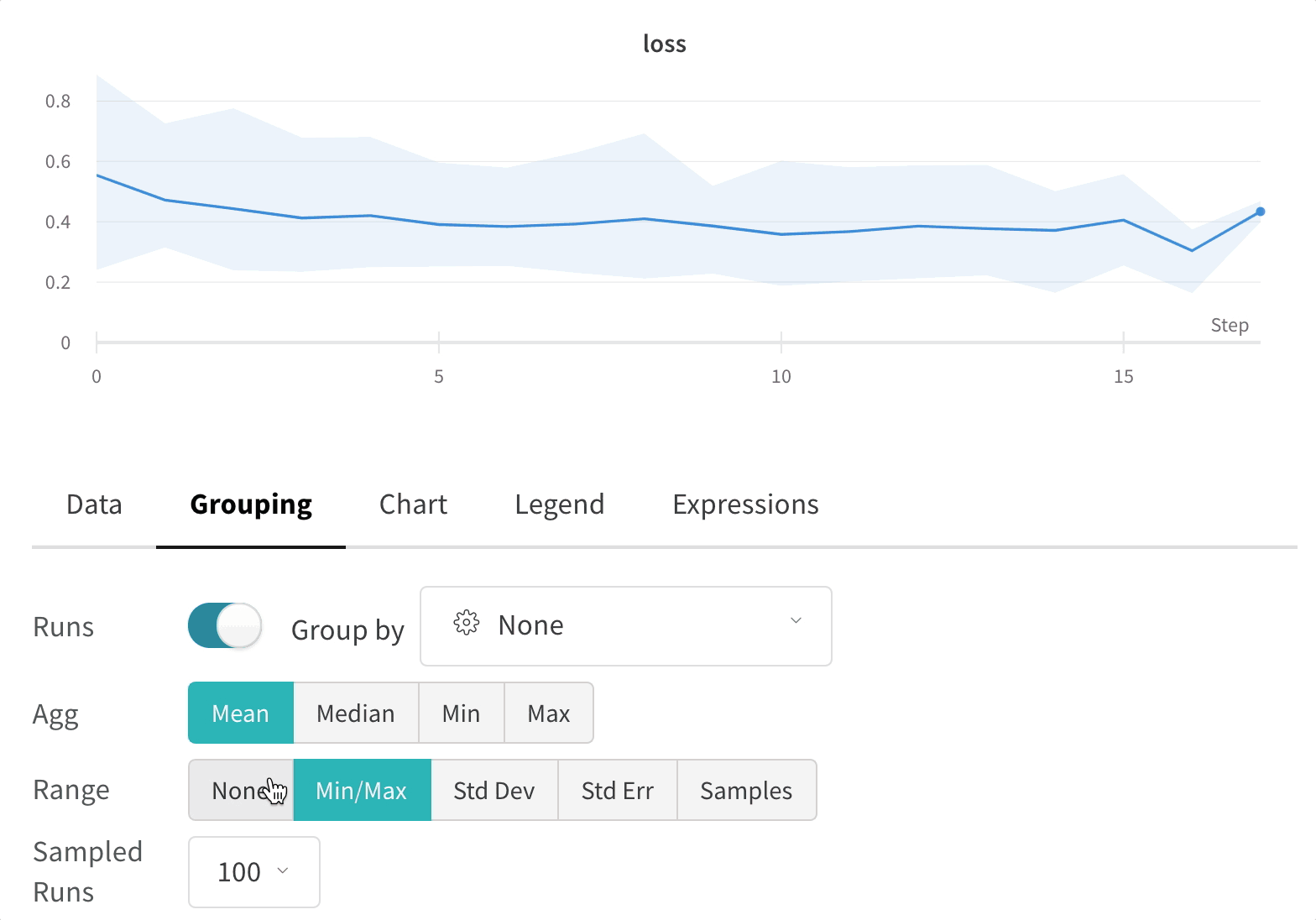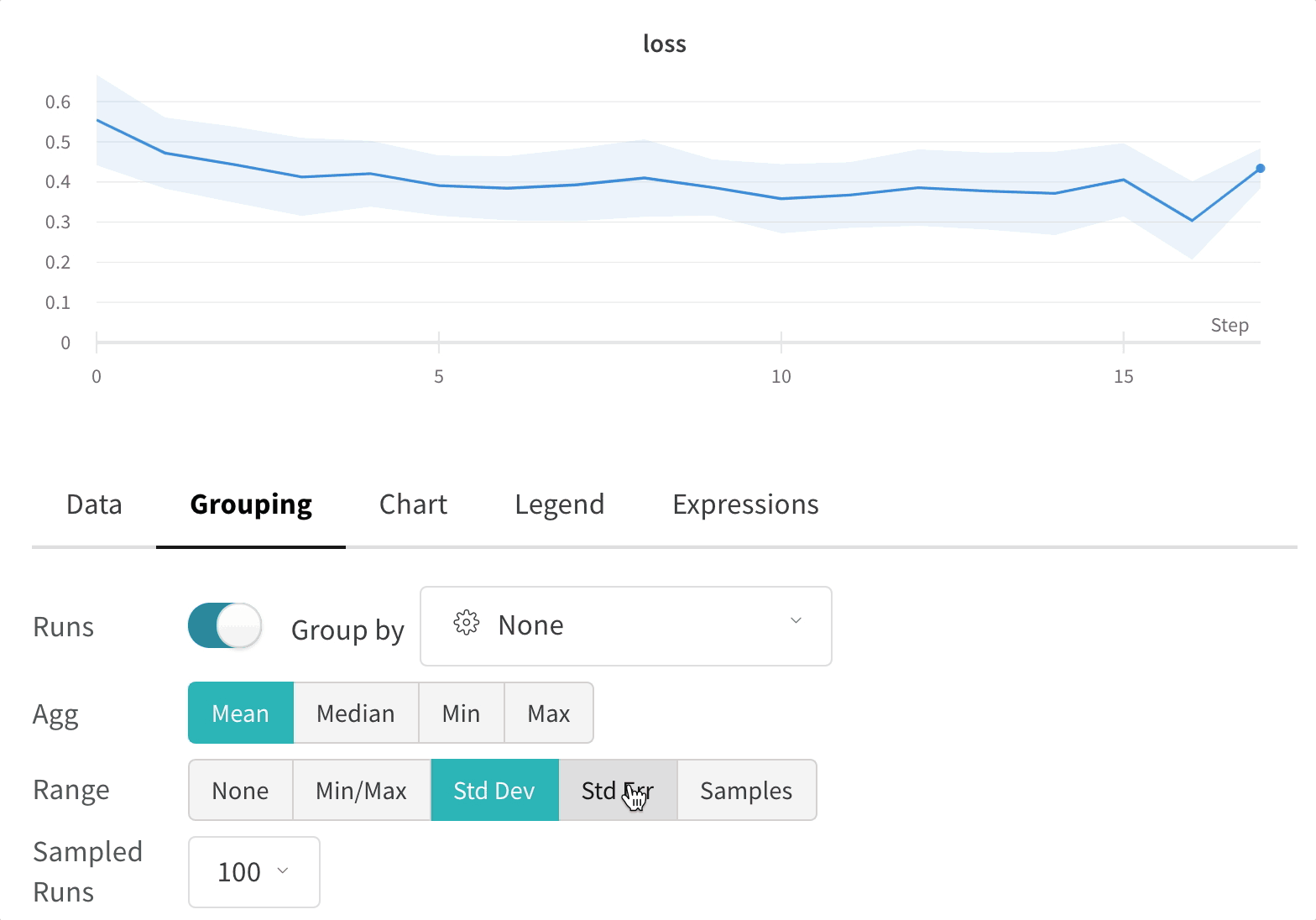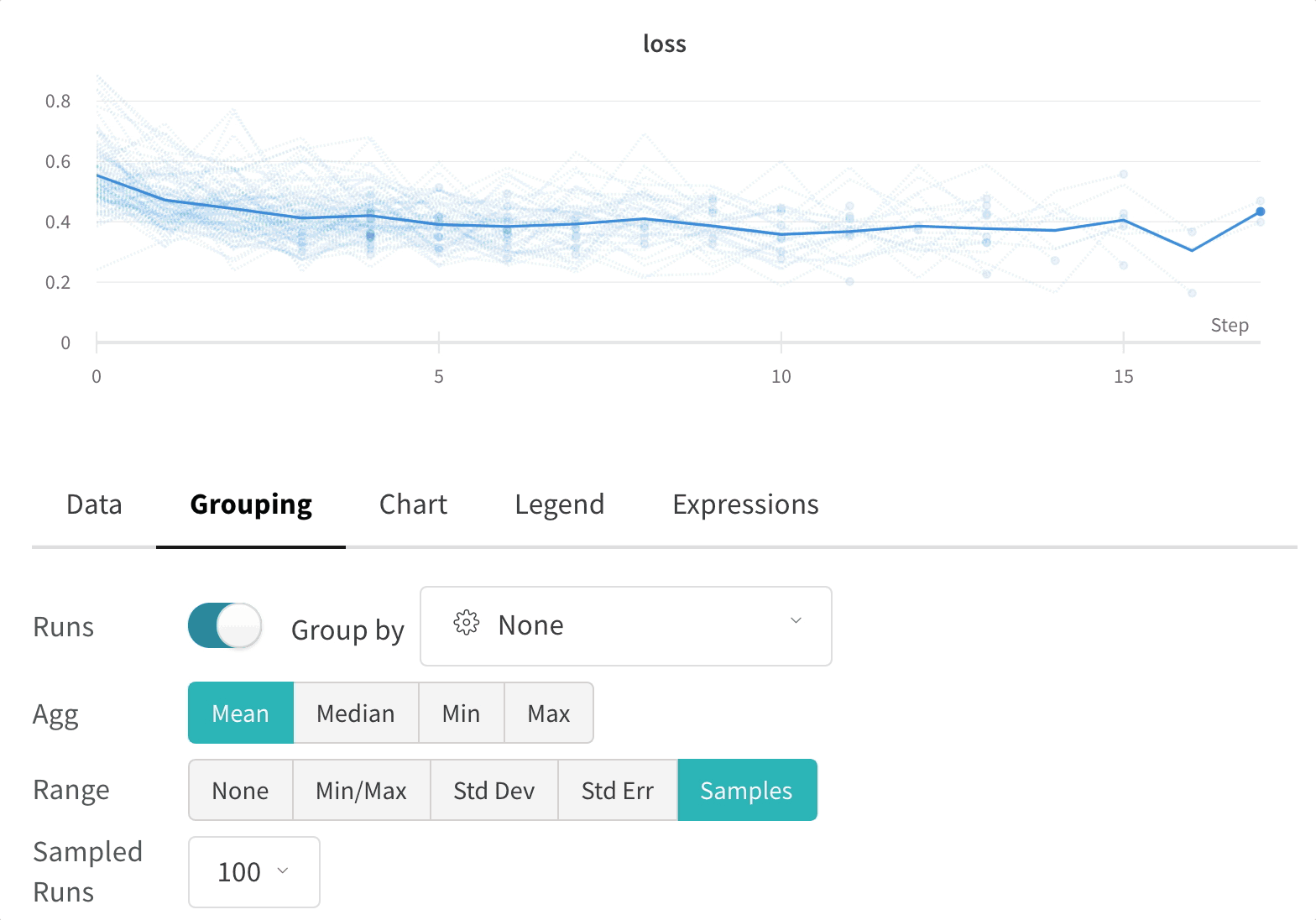
- Graphs: Each line represents the group's mean, and the shading indicates the variance. This behavior can be changed in the graph settings.
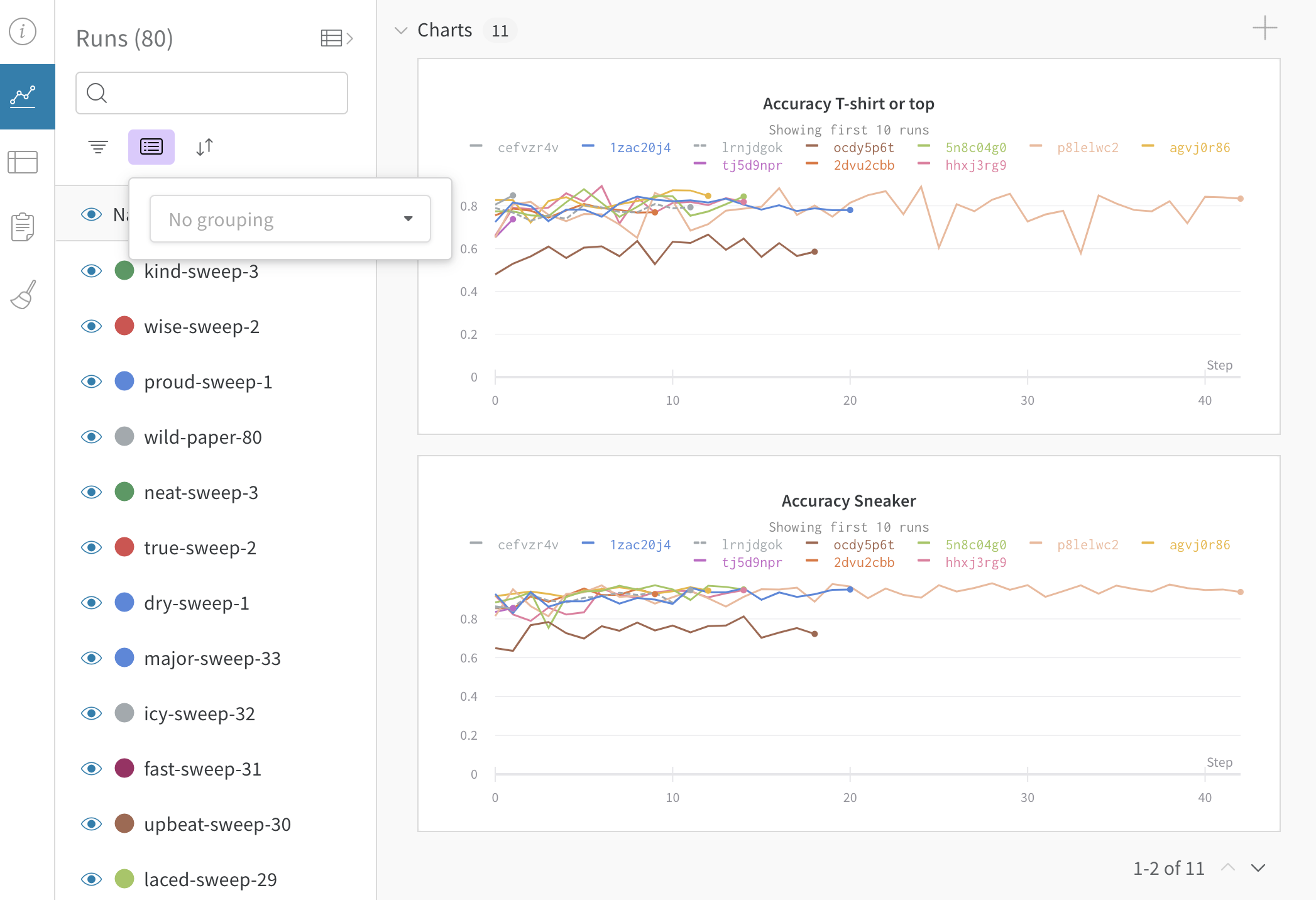
Turn off grouping
Click the grouping button and clear group fields at any time, which returns the table and graphs to their ungrouped state.
Grouping graph settings
Click the edit button in the upper right corner of a graph and select the Advanced tab to change the line and shading. You can select the mean, minimum, or maximum value for the line in each group. For the shading, you can turn off shading, and show the min and max, the standard deviation, and the standard error.
Common Questions
Can we group runs by tags?
Because a run can have multiple tags we don't support grouping by this field. Our recommendation would be to add a value to the config object of these runs and then group by this config value. You can do this with our API.